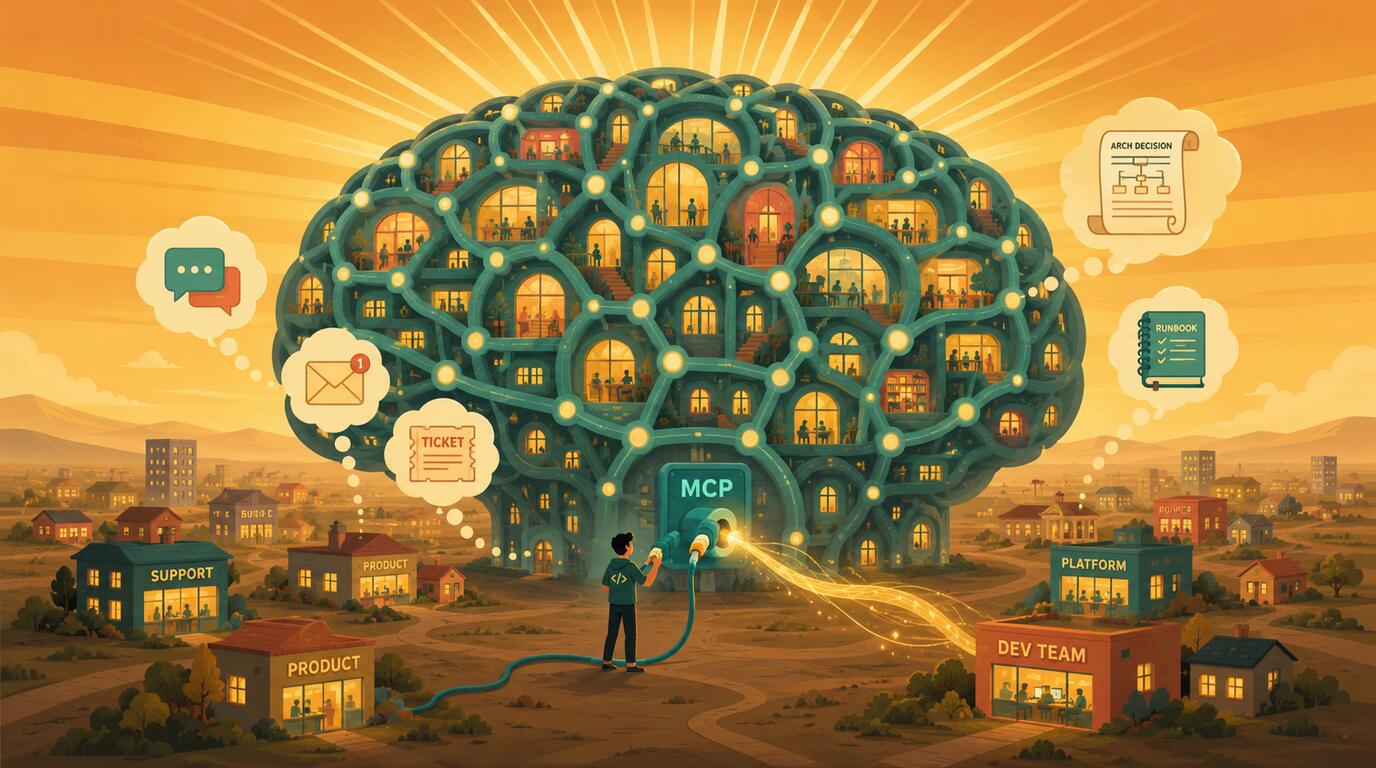

Ein Coding-Agent ohne Zugriff auf die Systeme des Teams arbeitet im Blindflug. Er sieht den Code im Arbeitsverzeichnis, sonst nichts. Ticket, Monitoring-Fehler, Datenbankschema, Architekturentscheidung von vor zwei Jahren: All das muss ein Mensch in den Chat kopieren.
Mit einem MCP-Server ändert sich das. Der Agent liest das Jira-Ticket selbst, sieht die zugehörigen Fehler in Sentry, fragt die Datenbank nach den betroffenen Datensätzen und öffnet am Ende einen Pull Request. Aus „der Agent kommentiert Code" wird „der Agent arbeitet in den Systemen eines Teams". Das ist der Grund, warum MCP 2026 zur gemeinsamen Anschlussfläche vieler Agentenplattformen geworden ist.
Genau daraus entsteht aber auch das Bedrohungsmodell. Derselbe Agentenlauf liest ein Ticket aus einer Quelle, der niemand vertraut, greift in eine produktive Datenbank und schreibt nach außen, sichtbar für andere. Dieselbe Reichweite, die den Agenten nützlich macht, ist die Stelle, an der aus Kontext eine Berechtigung wird. Beides stimmt gleichzeitig. Ein ehrlicher Text über MCP muss Nutzen und Risiko zusammen erklären.
Ein MCP-Server ist die Komponente, die diese Reichweite möglich macht. Das macht ihn zum richtigen Einstieg, wenn man verstehen will, was Coding Agents 2026 tatsächlich ausrichten können. Wer das größere Bild sucht, in dem Tooling, Messung und Kontrolle zusammenkommen, findet im Leitfaden, wie Coding Agents kontrolliert ins Entwicklerteam kommen. Dieser Beitrag konzentriert sich auf diese eine Komponente und ihre Folgen, im Guten wie im Schlechten.
Kurz gefasst: Ein MCP-Server verbindet einen Coding-Agenten standardisiert mit externen Systemen: Repository, Tickets, Datenbanken, Runbooks und dem Wissen eines Teams. Der Nutzen liegt nicht darin, dass ein Agent plötzlich APIs aufrufen kann, das konnte er vorher auch. Er liegt darin, dass sich Kontext und Werkzeuge wiederholbar und teamfähig anbinden lassen. Genau dieselbe Reichweite ist die Angriffsfläche: Was der Agent lesen, ausführen und nach außen schreiben darf, gehört über Rechte, Allowlisting, einen Audit-Trail und einen benannten Verantwortlichen kontrolliert.
Was ist ein MCP-Server?
Ein MCP-Server ist ein Dienst oder lokales Programm, das einer KI-Anwendung standardisiert Tools, Kontextdaten und Prompts bereitstellt. MCP steht für Model Context Protocol, einen offenen Standard, den Anthropic am 25. November 2024 vorgestellt und quelloffen veröffentlicht hat. Die Idee dahinter ist einfach: eine gemeinsame Schnittstelle, über die eine KI-Anwendung an Datenquellen, Werkzeuge und vorgefertigte Arbeitsabläufe andockt. Die offizielle Dokumentation nennt das den USB-C-Anschluss für KI-Anwendungen. Die Analogie erklärt die Standardisierung. Mehr nicht. USB-C sagt nichts darüber, welches System am anderen Ende hängt, was es darf und ob es etwas abfließen lassen kann.
Das Grundmodell besteht aus drei Rollen: Host, Client und Server. Der Host ist die KI-Anwendung selbst, also Claude Code, Cursor, VS Code oder Codex; welcher davon zum Team passt, ist eine eigene Entscheidung. Für jeden angebundenen Server verwaltet der Host einen eigenen Client, der die Verbindung verwaltet. Der Server stellt bereit, was der Agent nutzen soll. Die Kommunikation läuft über JSON-RPC. Als Transport dient entweder lokal stdio, wobei der Host den Server als Unterprozess startet, oder Streamable HTTP zu einem getrennt laufenden Dienst. Diese Transportwahl klingt nach einem Detail. Sie prägt später einen großen Teil des Risikoprofils.
Wichtiger als der Transport sind die drei Arten von Fähigkeiten, die ein Server anbietet:
- Tools sind Funktionen, die das Modell ausführen kann. Bei Coding Agents sind das die Hände: eine Datenbankabfrage absetzen, einen Branch anlegen, eine Datei schreiben.
- Resources sind Kontextdaten, die in den Modellkontext fließen: ein Datenbankschema, eine Datei, eine API-Antwort. Das Material, mit dem der Agent arbeitet.
- Prompts sind wiederverwendbare Vorlagen, oft als Slash-Kommando, also standardisierte Arbeitsanweisungen.
Diese Dreiteilung ist nicht nur Terminologie. Sie ist der Grund, warum ein MCP-Server gleichzeitig nützlich und heikel ist. Tools führen Aktionen aus, Resources bringen externe Inhalte in den Modellkontext, und beides passiert in demselben Modelllauf.
Was der Agent durch einen MCP-Server gewinnt
Ohne MCP kann ein Coding-Agent das, was sein Host ihm erlaubt: Dateien im Arbeitsverzeichnis lesen und ändern, Tests laufen lassen, Code erklären und Diffs vorbereiten. Alles andere, jedes externe Signal, muss ein Mensch in den Chat kopieren. Die Akzeptanzkriterien aus Jira, der Stacktrace aus Sentry, das Schema aus der Datenbank, der Designstand aus Figma. Der Mensch wird zur Integrationsschicht. Das ist langsam, unvollständig und schwer nachzuvollziehen.
Ein MCP-Server verschiebt diese Grenze. Der Agent entdeckt die verfügbaren Tools und Resources selbst, ruft konkrete Tools auf und benutzt externe Systeme als Teil eines Arbeitslaufs. Die Claude-Code-Dokumentation beschreibt das ausdrücklich als den Weg, ein System „direkt zu lesen und darin zu handeln", statt mit eingefügten Daten zu arbeiten. Aus „der Agent kommentiert Code" wird „der Agent handelt in Systemen".
Welche Fähigkeiten der Agent dadurch bekommt, hängt vom Server ab. Die folgende Übersicht zeigt beide Seiten nebeneinander, weil beide zusammengehören: was der Agent gewinnt und was Teams dabei kontrollieren müssen.
| Server | Was der Agent gewinnt | Was Teams dabei kontrollieren müssen |
|---|---|---|
git / Filesystem | Repository-Historie, Diffs, lokale Dateien, Branch-Operationen | Lokale Dateien, Secrets und Build-Artefakte geraten in Reichweite. Deny-Regeln und Workspace-Grenzen zählen. |
github mcp server | Issues, Pull Requests, Code-Dateien, Review-Anfragen, Security Advisories | Der Agent reicht so weit wie das GitHub-Token. Die Grenze zwischen öffentlichen und privaten Repos wird kritisch. |
jira / Atlassian Rovo | Tickets suchen, zusammenfassen, anlegen, aktualisieren; Confluence- und Bitbucket-Kontext | Ticketinhalte sind oft nicht vertrauenswürdig. Der Client handelt mit den Rechten des Nutzers. |
postgres | Schema lesen, Daten abfragen, je nach Tool auch ändern | Der Datenbankzugriff wird über den Prompt steuerbar. Read-only-Nutzer, Zeilenpolicies und Query-Limits sind Pflicht. |
playwright / Browser | UI-Tests, Screenshots, Navigation, Designabgleich | Webinhalt ist nicht vertrauenswürdig. Browser-Tools taugen als Einfallstor und als Kanal nach außen. |
slack / Mail | Nachrichten suchen, Entwürfe erzeugen | Ein starker Kanal nach außen. In Kombination mit Repo- oder Datenbankzugriff besonders heikel. |
Zwei realistische Abläufe machen das greifbar. Vom Ticket zum Pull Request: Der Agent liest Jira ENG-4521 samt Confluence-Kontext, sucht die betroffenen Dateien im Repo, fragt Sentry nach den passenden Fehlern, ändert den Code, lässt die Tests laufen und öffnet einen Pull Request. Ohne MCP müsste der Entwickler jedes dieser Signale von Hand zusammentragen. Mit MCP ist es ein Agentenlauf. Von der Datenbankdiagnose zum Fix: Der Agent liest einen Bugreport, fragt das Postgres-Schema als Resource ab, ruft ein read-only Query-Tool auf, um die betroffenen Datensätze zu verstehen, ändert die Validierungslogik und ergänzt Tests. Das ist überall dort nützlich, wo der Datenbankkontext für den Bug entscheidend ist.
Hinter den einzelnen Tools stehen drei Gewinne, die über den einzelnen Aufruf hinausreichen.
Weniger Kontextverlust. Heute kopiert ein Entwickler Tickettexte, Logs, Stacktraces und Datenbankbefunde von Hand in den Chat, mit allen Auslassungen und Tippfehlern, die dabei passieren. Ein MCP-Server holt diesen Kontext kontrolliert aus den Originalsystemen. Das ist nachvollziehbarer und weniger fehleranfällig.
Wiederholbare Abläufe. Prompts sind der dritte Grundbaustein. Sie sind keine statischen Vorlagen. Die VS-Code-Dokumentation beschreibt sie als kontextbewusste Arbeitsabläufe, die direkt als Slash-Kommando erscheinen. Ein neuer Agent kann dieselben Quellen und Abläufe nutzen wie die bereits freigegebenen Agenten. Das Verhalten der Agenten wird wiederholbarer, statt von der Tagesform eines einzelnen Prompts abzuhängen.
Bessere Patches. Ein Agent, der das reale Schema, die letzten Incidents und die Testkonventionen eines Teams lesen kann, schreibt nicht irgendeinen technisch plausiblen Fix, sondern einen, der zum Betrieb passt. Das ist ein anderes Versprechen als „spart Klicks".
Die größere Chance: der gemeinsame Unternehmenskontext
Die einzelnen Tools sind nur der sichtbare Teil. Die interessantere Nutzung ist nicht der einzelne Aufruf von GitHub oder Postgres, sondern der gemeinsame Kontext eines ganzen Unternehmens.
Y Combinator beschreibt dieses Problem in seinen aktuellen Requests for Startups sehr pointiert. YC-Partner Tom Blomfield schreibt, der größte Engpass für die Automatisierung von Unternehmen seien nicht mehr die Modelle. Die Modelle seien inzwischen gut genug. Der Engpass sei das Domänenwissen. Es stecke in den Köpfen der Leute, in alten E-Mail-Konten, Slack-Verläufen, Support-Tickets und Datenbanken. Was fehle, sei eine lebende Karte davon, wie ein Unternehmen funktioniert, so strukturiert, dass KI sie nutzen kann. In der Startup-Szene läuft das unter dem Stichwort „Company Brain". Für deutsche Unternehmen klingt das schnell nach Startup-Sprech. Gemeint ist aber etwas Vertrautes: aktuelles, berechtigungsgeprüftes Wissen darüber, wie das Unternehmen wirklich arbeitet.
Für Coding Agents ist das konkreter, als es klingt. Ein Agent braucht nicht nur GitHub und eine Datenbank. Er braucht die Regeln und Entscheidungen des Teams: Architekturentscheidungen und ihre Begründung, Postmortems vergangener Incidents, Runbooks, wer fachlich für einen Dienst verantwortlich ist, welche Migrationsregeln gelten, welche Metrikdefinitionen verbindlich sind. Genau dieses Wissen entscheidet, ob ein Patch zur Architektur passt und im Betrieb tragfähig ist, oder nur zur Fehlermeldung.
Ein Beispiel zeigt, was das im Alltag ändert. Ein Agent soll einen Timeout-Bug im Checkout beheben. Aus GitHub kennt er den Code, aus Sentry den Fehler. Aus dem gemeinsamen Unternehmenskontext kennt er zusätzlich die Architekturentscheidung, die synchrone Zahlungsaufrufe verbietet, das letzte Postmortem zu Retry-Stürmen und die Teamregel, dass Änderungen an der Zahlung immer einen Idempotency-Test brauchen. Erst damit wird aus einem plausiblen Patch ein Patch, der zum Betrieb passt.
Ein MCP-Server ist dabei nicht das Company Brain selbst. Aber er ist die naheliegende Schnittstelle, über die ein Agent eine solche Wissensschicht liest, Abläufe abruft und Änderungen nachvollziehbar zurückmeldet. Die ersten von Y Combinator finanzierten Firmen bauen genau darauf: Produkte, die sich als „Company Brain" für die Agenten eines Teams beschreiben und über MCP angebunden werden, oder als „permissioned context graph", aus dem jeder Agent liest und in den er zurückschreibt. Das sind Eigenangaben der Anbieter, kein geprüftes Ergebnis. Aber die Richtung ist deutlich.
Damit bekommt auch die Sicherheitsfrage eine zweite Seite. Die Alternative zu einem kontrollierten MCP-Server ist selten „kein Zugriff". Sie ist Copy-Paste, Schatten-Integrationen und die persönlichen Tokens einzelner Entwickler, verstreut über Laptops und Skripte. Ein sauber betriebener MCP-Server kann Rechte, Audit und Datenklassifizierung an einer Stelle bündeln, statt sie dem Zufall zu überlassen. Die Reichweite bleibt heikel. Aber sie wird kontrollierbar, und das ist mehr, als der heutige Normalzustand vieler Teams bietet.
MCP ist nicht Function Calling. Der Durchbruch liegt woanders
An dieser Stelle lohnt eine Entzauberung, denn der Markt verkauft jeden Anschluss als Sensation. Konnte ein Agent vorher keine API aufrufen? Doch, natürlich. Function Calling heißt: Eine Funktion wird mit Schema direkt an ein Modell angebunden. Das gibt es länger. Das Modell erzeugt einen Tool-Aufruf, die Anwendung führt ihn aus, das Ergebnis kommt zurück. MCP ersetzt das nicht. Es standardisiert, wie ein externer Server Tools, Resources und Prompts anbietet und wie ein beliebiger Host sie entdeckt, konfiguriert und aufruft.
Der Durchbruch liegt also nicht in einer neuen Grundfähigkeit. Er liegt in der Standardisierung. Vor MCP musste jeder Tool-Anbieter seine Integration pro Host neu bauen, N Hosts × M Tools. Mit MCP baut er einen Server, und beliebig viele Agenten nutzen ihn. Aus vielen einzelnen Integrationen wird eine gemeinsame Anschlussfläche. Das senkt den Aufwand, macht Tooling portabel und wiederholbar, und genau das macht es teamrelevant. Für eine einzelne Modellfähigkeit ist MCP kein Durchbruch. Für Teams, Tool-Anbieter und Governance ist die Standardisierung sehr wohl ein Durchbruch.
Daraus folgt, was MCP ausdrücklich nicht ist. Kein Agent, kein Modell, kein Ersatz für Review und vor allem kein Berechtigungsmodell. Eine API ist die eigentliche Daten- oder Geschäftsschnittstelle. Ein MCP-Server ist eine agentenfreundliche Hülle um diese Schnittstelle. Diese Hülle entscheidet nicht, ob ein Tool sicher ist, ob ein Scope sinnvoll geschnitten wurde oder ob der Agent vernünftig handelt. Wer einen MCP-Server anschließt, hat einen Stecker verbunden, keine Sicherheitsarchitektur.
Vom Anthropic-Feature zum Anschlussstandard
Wird daraus ein bleibender Standard oder bleibt MCP ein Strohfeuer von 2025? Die Adoption auf Anbieterseite spricht eher für einen dauerhaften Standard. Anthropic stellte MCP Ende November 2024 als offenen Standard vor, samt erster Server für Google Drive, Slack, GitHub, Git, Postgres und Puppeteer. Im Laufe des Jahres 2025 zogen wichtige Anbieter nach: OpenAI band Remote-MCP in seine Responses API ein, GitHub machte seinen Remote-MCP-Server im September 2025 allgemein verfügbar, und Google kündigte im Dezember 2025 vollständig verwaltete Remote-MCP-Server für seine Dienste an. Seit März 2026 werden sie bei unterstützten Diensten automatisch aktiviert, und seit dem 1. Mai 2026 sind die Google- und Google-Cloud-Remote-MCP-Server allgemein verfügbar, wobei einzelne Server weiterhin im Preview-Status sein können. Im selben Monat kam MCP unter das Dach der Agentic AI Foundation bei der Linux Foundation. Die US-Behörde NSA nennt MCP in ihrer Leitlinie vom Mai 2026 den „de facto standard" für die Kommunikation in einem wachsenden Ökosystem KI-gestützter Dienste, und sie rät nicht ab, sondern zur kontrollierten Einführung.
Bei den Ökosystemzahlen ist Vorsicht angebracht, denn sie stammen vor allem von den Anbietern selbst. Anthropic meldete im Dezember 2025 mehr als 10.000 aktive öffentliche Server und über 97 Millionen monatliche SDK-Downloads für Python und TypeScript zusammen. Nützliche Orientierungspunkte, aber Eigenangaben, keine unabhängige Marktstatistik. Eine hohe Serverzahl sagt nichts über gepflegte, produktionsreife oder sichere Server. Der ehrliche Befund: MCP hat sich binnen eines Jahres zum Anschlussstandard vieler Agenten-Tools entwickelt, doch die Governance- und Sicherheitsreife hinkt der Adoption hinterher.
Dieselbe Reichweite ist die Angriffsfläche
Die Angriffsfläche eines MCP-Servers ist keine Nebenwirkung, die man wegkonfigurieren könnte. Sie ist dieselbe Eigenschaft, die ihn nützlich macht. Die MCP-Spezifikation sagt das ungewöhnlich offen: Das Protokoll ermögliche mächtige Fähigkeiten über „arbitrary data access and code execution paths", also weitreichenden Datenzugriff und Wege zur Codeausführung, und verlange deshalb ausdrücklich Zustimmung, Kontrolle, Datenschutz und Tool-Sicherheit. Kontrolle ist also kein nachträgliches Extra, sondern Teil dessen, was der Standard von Implementierungen erwartet.
Greifbar wird das an den Mechanismen, über die diese Reichweite missbraucht werden kann.
Prompt Injection über Resources. Resources sind Kontextdaten, und Kontextdaten können Anweisungen enthalten. Sobald ein Agent eine Jira-Beschreibung, einen PR-Kommentar, eine fremde README oder eine über ein Browser-Tool geladene Webseite verarbeitet, kann darin eine Instruktion stehen, die nicht vom Nutzer kommt. Das ist kein MCP-spezifisches Problem, aber MCP macht es häufiger und systematischer, weil externe Inhalte leichter in den Agentenlauf gelangen.
Tool Poisoning und Line Jumping. Heikler noch ist, dass schon die Tool-Beschreibung selbst Prompt Injection enthalten kann. Der Client fragt beim Verbinden die Tool-Liste ab, und damit gelangen die Beschreibungen in den Modellkontext, bevor überhaupt ein Tool aufgerufen wird. Die übliche Freigabe-Oberfläche greift aber erst beim Aufruf. Wenn schon die Beschreibung das Modellverhalten manipuliert, entsteht das Risiko, bevor der Nutzer überhaupt bestätigen kann. Die Spezifikation zieht daraus selbst die Konsequenz: Clients müssen Tool-Annotationen als nicht vertrauenswürdig behandeln, solange sie nicht von einem vertrauenswürdigen Server stammen.
Die lethal trifecta. Simon Willison prägte im Juni 2025 ein Bild, das hier besser passt als ein pauschales „MCP ist unsicher". Gefährlich wird ein Agent, wenn drei Dinge zusammentreffen: Zugriff auf private Daten, Verarbeitung nicht vertrauenswürdiger Inhalte und ein Kanal nach außen. Für Coding Agents ist das keine Theorie. Viele reale Workflows bringen diese drei Elemente zusammen. Private Daten sind das Repo, die .env, die Datenbank, interne Confluence-Seiten. Nicht vertrauenswürdig sind Ticket-Texte, PR-Kommentare, Webseiten, Logs. Der Kanal nach außen ist die PR-Beschreibung, der öffentliche Kommentar, Slack, das HTTP-Tool. Der Ablauf vom Anfang dieses Beitrags vereint alle drei in einem Lauf.
OAuth, Scopes und das „handelt im Namen des Nutzers"-Problem. Remote-Server authentifizieren sich typischerweise über OAuth oder Bearer-Tokens, und die Empfehlungen lauten auf OAuth 2.1, kurzlebige Tokens und Rotation. Doch das eigentliche Problem ist selten „OAuth ja oder nein", sondern der Zuschnitt der Berechtigungen. Der MCP-Client handelt mit den bestehenden Rechten des Nutzers. Darf der Agent in allen Repos lesen? In privaten schreiben? Ist der Datenbanknutzer wirklich read-only? Ein zu weit gefasster Scope macht aus einem harmlosen Lauf einen weitreichenden Zugriff.
Bleibt der Unterschied zwischen den beiden Transportwegen. Ein lokaler stdio-Server ist bequem und schnell, läuft aber als Prozess mit den Rechten des Nutzers, samt Zugriff aufs Dateisystem. Die Sicherheitsempfehlungen raten zu Sandbox und minimalen Rechten. Ein Remote-HTTP-Server vermeidet die lokale Prozessausführung, holt sich dafür aber die klassischen Web-Risiken ins Haus: Authentifizierung, Session-Hijacking, Origin-Prüfung, DNS-Rebinding, SSRF, Mandantentrennung. Die nüchterne These: Für Einzelne ist stdio praktisch, für Teams ist ein Remote-Server oft besser zu kontrollieren, aber nur, wenn OAuth, Audit, Rate-Limits und Allowlisting sauber gelöst sind. Und ein verbreiteter Trugschluss gehört ausgeräumt: dass read-only unproblematisch sei. Read-only genügt für Exfiltration, sobald der Agent private Daten lesen und an anderer Stelle schreiben oder senden kann. Die lethal trifecta braucht nur einen einzigen Schreibkanal.
Das Risiko ist besser belegt als der Schaden
Nach gut einem Jahr Praxis ist die Schadenslage dünner belegt als die Risikolage, und das ist selbst ein Befund. Belegt sind starke Machbarkeitsnachweise: Invariant Labs zeigte, wie ein bösartiges GitHub-Issue einen Agenten über den GitHub-MCP-Server dazu bringt, Daten aus privaten Repositories abfließen zu lassen; Trail of Bits demonstrierte, wie manipulierte Tool-Beschreibungen die Gesprächshistorie abgreifen. Sauber als CVE dokumentiert ist vor allem CVE-2025-49596 im MCP Inspector, einem Entwicklungswerkzeug zum Testen von MCP-Servern, behoben in Version 0.14.1. Bezeichnend ist, dass das ein Fehler in einem Werkzeug der Toolchain war, nicht im Protokoll. MCP-Sicherheit hängt an Clients, Devtools und Server-Implementierungen, nicht nur am Standard.
Was es aus den geprüften Quellen nicht gibt, ist eine belastbare, unabhängige Statistik zu breiten realen Schäden. Eine vieldiskutierte Veröffentlichung von OX Security vom April 2026 stellt zwar mehrere STDIO-Schwachstellen als systemisches Problem im Kern von MCP dar, doch die Gegenposition sieht die Ursache in den Anwendungen, die nicht vertrauenswürdige Eingaben an die lokale Prozessausführung weiterreichen, nicht im Protokoll. Wer „MCP ist Remote-Code-Ausführung per Design" liest, liest eine Interpretation, keine gesicherte Lage. Das Risiko ist also strukturell gut belegt, die öffentliche Vorfalllage noch dünn. Genau deshalb gehören die Kontrollen vor den Rollout, nicht erst nach dem ersten großen Vorfall.
Was ein Team prüft, bevor der erste Server angeschlossen wird
Aus alldem folgt keine Warnung, sondern eine Reihenfolge, und die zahlt sich aus. Ein kuratierter, kontrollierter Zugang ist nicht nur sicherer als verstreute Tokens und Schatten-IT, er ist auch der einzige, den man später gegenüber einer Aufsicht belegen kann. Ein MCP-Server ist genau so ein Lieferkettenelement, das man in regulierten Umgebungen ohnehin dokumentieren und absichern muss. Least Privilege, Allowlisting freigegebener Server, ein Audit-Trail, getrennte Lese- und Schreibflächen und ein benannter Verantwortlicher sind keine Enterprise-Extras. Sie sind die Voraussetzung dafür, einem Agenten überhaupt einen MCP-Server zu geben. Fünf Prüfpunkte bündeln das.
- Herkunft des Servers. Wer betreibt ihn: ein offizieller Anbieter, eine interne Plattform, ein einzelner Maintainer, ein unbekannter Paketautor? Kommt er aus einer kuratierten Registry oder direkt aus npm? Lässt sich die Version festschreiben und vor der Teamfreigabe prüfen? Die NSA empfiehlt gepflegte, unterstützte Projekte, strenge Reviews und interne Registries.
- Scope und Rechte. Getrennte Server oder Toolsets für Lesen und Schreiben. Read-only-Datenbanknutzer. Repo-spezifische statt org-weiter GitHub-Rechte. OAuth 2.1 statt langlebiger Tokens, wo möglich.
- Host-Kontrollen. Welche Hosts dürfen MCP nutzen, und gibt es Allowlists für Server-Identitäten, nicht nur für Namen? Claude Code unterstützt verwaltete Konfigurationen mit Allow- und Deny-Listen, Codex Enterprise aktiviert Server nur bei passender Identität, VS Code hat eine Org-Policy. Die Hebel sind vorhanden. Teams müssen sie nur nutzen.
- Sandbox und Grenzen. Lokale
stdio-Server in einem Container oder unter einem eingeschränkten Nutzerkonto ausführen, mit Deny-Regeln für.env, Secrets und SSH-Keys. Remote-Server nicht offen auf0.0.0.0betreiben, mit geprüftem Origin-Header. - Audit und Monitoring. Tool-Aufrufe mit Nutzer, Server, Tool, Eingabe, Zeit und Entscheidung protokollieren, SIEM-fähig, mit Alerts für verdächtige Kombinationen, etwa „liest privates Repo" plus „postet öffentlichen Kommentar". Dazu ein Inventar aller Server, Versionen, Tokens und Verantwortlichen.
Daraus ergibt sich eine Faustregel für die Einführung. Die erste Freigabe sollte nicht „GitHub plus Jira plus Postgres plus Slack plus Browser" heißen. Sicherer ist ein gestuftes Modell: erst read-only Resources und risikoarme Tools, dann ein Server pro System mit minimalem Scope, menschliche Freigabe für jede Schreibaktion, und keine Kombination aus privater Datenquelle, nicht vertrauenswürdigen Inhalten und Schreibkanal nach außen ohne zusätzliche Policy. Erst wenn Audit und Logging nachweislich funktionieren, sollte der Rollout auf Teamebene beginnen. Wer Scope und Datenflüsse so sauber schneiden will, landet schnell bei der Frage, was der Agent überhaupt sehen darf.
Fazit
Ein MCP-Server ist kein Produkt, kein Agent und keine Magie. Er ist die standardisierte Schnittstelle, mit der ein Coding-Agent in die Systeme und das Wissen eines Teams greift: ins Repo, ins Ticketsystem, in die Datenbank, in Runbooks und Architekturentscheidungen. Darin liegt der eigentliche Nutzen. Er macht Agenten nicht nur mächtiger, er macht den Kontext eines Unternehmens für Agenten nutzbar, und das ist der Grund, warum sich 2026 viele große Agentenplattformen auf MCP geeinigt haben.
Dieselbe Reichweite ist die Angriffsfläche. Das ist kein Alarmismus, das steht so in der Spezifikation, die ausdrücklich Zustimmung, Kontrolle und Tool-Sicherheit verlangt. Wer einen MCP-Server anschließt, verwandelt Kontext in Berechtigung: Was vorher Chat war, wird Datenbankabfrage, GitHub-Schreibzugriff, Jira-Änderung, Slack-Nachricht. Ob daraus Nutzen oder Schaden wird, entscheidet nicht das Protokoll, sondern Least Privilege, Allowlisting, ein Audit-Trail und ein benannter Verantwortlicher. Nutzen und Kontrolle sind hier keine Gegensätze. Ohne Kontrolle bleibt MCP ein Risiko. Mit Kontrolle wird es zur tragfähigen Anschlussfläche für Agentenarbeit.
Quellen
- Anthropic: Introducing the Model Context Protocol (25. November 2024)
- Model Context Protocol: Spezifikation samt Sicherheitsabschnitt (Stand 25. November 2025)
- OpenAI: MCP and Connectors, Remote-MCP in der Responses API
- GitHub Changelog: Remote GitHub MCP Server is now generally available (4. September 2025)
- Google Cloud: Announcing official MCP support for Google services (Dezember 2025) und die Release Notes zur GA am 1. Mai 2026
- Anthropic: Donating the Model Context Protocol and establishing the Agentic AI Foundation (Dezember 2025)
- NSA: Cybersecurity Information Sheet Model Context Protocol (MCP): Security Design Considerations for AI-Driven Automation (Mai 2026)
- NVD: CVE-2025-49596, MCP Inspector, behoben in 0.14.1
- Y Combinator: Requests for Startups zum „Company Brain"
- Invariant Labs: GitHub MCP Exploited, Machbarkeitsnachweis zur Repo-Exfiltration
- Trail of Bits: Jumping the line: How MCP servers can attack you before you ever use them, Tool Poisoning über Tool-Beschreibungen
- Simon Willison: The lethal trifecta for AI agents (16. Juni 2025)

